OpenPose를 이용한 사람의 움직임 감지(Human Pose Estimation)
OpenPose를 이용한 사람의 움직임 감지(Human Pose Estimation)
file:///D:/01-Tomato/work/work_AI/Posenet/Real-Time-Human-Pose-detection-in-browser-master/Real-Time-Human-Pose-detection-in-browser-master/poseNet%20with%20webcam/index.html
기존의 머신러닝을 사용하기 전에는 영상 내에서 인간의 움직임을 감지하기 위해서 Xbox의 "키넥트 센서"와 같은 전용 기기를 사용하여, 인간의 몸짓을 비롯한 제스처를 인식할 수 있었다.
이번 포스팅에서는, 이러한 인간의 몸짓을 감지하기 위한 특수한 센서가 없이 순수하게 영상 데이터만으로 인간의 움직임을 추정하고 감지할 수 있는 Open Pose DNN에 대해 알아보고 이걸 이용해 간단하게 실습을 수행해보자.
움직임 추정(Keypoint Detection)
OpenPose는 딥러닝의 CNN 기반으로 이미지 혹은 영상을 입력 값으로 하여 객체의 위치 및 방향을 감지한다. OpenPose가 작동되는 신경망 아키텍처는 다음과 같다.
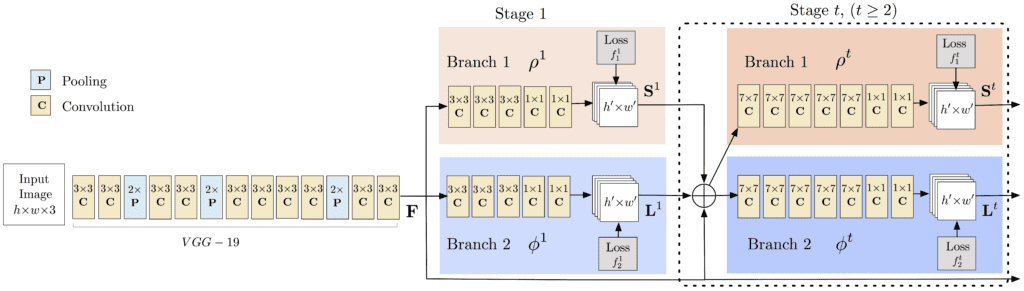
1. 좌측단의 입력 데이터를 VGGNet - 19를 통해 수행된 Output 데이터의 특징(feature)을 강조한 상태로 출력하게 된다.
2. 1번에서 출력된 Output을 2번의 분기를 통해 전파를 수행하게 되는데, 첫 번째 분기점에서는 전반적인 신체 부위의 특정(팔꿈치, 무릎 등)에 사용된다.
3. 반복되는 Stage에 따라 가지를 거쳐서 confidence map과 affinity field를 구하게 되는데, 여기서 confidence map은 인간의 관절 구조 등을 찾는데 사용되며, affinity field는 추출된 관절 구조가 어떤 객체의 것인가에 대해 알아는데 사용된다.
예를 들어 인간의 오른쪽 어깨에 대한 confidence map은 다음과 같이 형성된다.

그 후, 지속적으로 다음 분기를 거쳐가며 인간의 각 부위 간 유사성에 기반하여 2D vector fields를 예측하게 된다. 아래의 그림은 위에서 잡은 왼쪽 어깨와 목덜미의 유사성을 표시한 그래프이다.

4. 위에서 연산된 confidence map과 affinity field로 이미지에 존재하는 사람들의 Keypoint를 예측하고 생성한다. 위와 같은 과정을 반복하여 학습하면 결과적으로 open pose를 완성할 수 있게 된다.
Pre-Trained 모델 사용하기
Keypoint Dection을 학습시키기 위한 많은 예제 데이터셋이 존재하지만, 이 포스트에서는 이미 학습되어 있는 모델을 OpenCV로 로드하여 실습을 수행해보겠다.
해당 모델은 모두 이 포스트 하단에 남긴 논문의 저자가 직접 개발한 것으로 Multi-Person Dataset (MPII)과 COCO dataset으로 학습된 2가지 모델이 존재한다.
MPII의 경우, 최대 18개의 점으로 인간의 자세를 감지하며, COCO는 15개의 점을 사용한다. 이외에도 직접 예측을 수행해보면 어느정도 Detection을 수행하는데에 다른 기준이 있음을 알 수 있다.

각 모델은 아래의 링크를 통해 다운로드받을 수 있다.
MPII Model
COCO Model
예제 코드를 통한 구현
위 모델을 사용하여 직접 이미지에 대한 자세 추정을 수행해보자. 아래의 링크는 실습에서 사용할 예제 코드이다.
아래는 이미지를 입력받아 해당 이미지 안에 있는 사람의 자세를 추정한 후, 스켈레톤 이미지를 그려주는 예제 코드의 일부분이다. 사실 뭐.. 모델 학습 과정 자체가 중요한 거지, 예측하는 코드는 딱히 어렵지 않다.



댓글
댓글 쓰기